



機(jī)床主軸溫度測點(diǎn)的 K-means 優化及試驗
2020-4-10 來(lái)源:南通大學機械工(gōng)程 南通第五機床 作(zuò)者:周成 莊麗(lì)陽(yáng) 袁江 高傳耀
摘要:針對機(jī)床熱誤差補償(cháng)技術中溫度(dù)測點的優化(huà)選擇,提出一種基於 K-means 算法和(hé) Pearson 相關係數相結合的方法(fǎ)。通過 K-means 算法將不(bú)同位置測點的(de)溫度進行聚類,用(yòng) Pearson 相關(guān)係(xì)數計算溫度與(yǔ)主軸熱誤差之間的相關性,從每一類別(bié)中選出一個最優測點組成最優測點組合,並對最優測點處(chù)的結果進行熱誤差建模(mó)。在立式加工中心 VMC850E上對該方法進行了試驗驗證,將溫度(dù)測點的數量(liàng)由 8 個減(jiǎn)少至 2 個。經方差(chà)分析和 F 檢驗(yàn),驗(yàn)證了最優測點處的溫度與熱變形之間顯著線性,模型(xíng)可靠。
關鍵詞:主軸;K-means 算法;Pearson 相(xiàng)關係數;測點優化
1 、引(yǐn)言
在實際生產過程中,機床零部件的發熱最終會導致主軸在軸(zhóu)向產生偏移,對產品的加工精度(dù)造成影響,甚至產生報廢品[1-2]。大量研究表明,機(jī)床(chuáng)熱誤差已經取代(dài)幾(jǐ)何誤差,成為最主的誤差源,減小熱誤差已經成為(wéi)企業亟待解(jiě)決的問題之一。熱誤差補償(cháng)技術相比機床結構改進,是減小熱誤差、提高加(jiā)工(gōng)精度的更加有效、經濟的方法。而溫(wēn)度測點的優(yōu)化布置是實現熱誤差補償的重點,其優化結(jié)果的有效性大大影(yǐng)響著熱(rè)誤差補償的精度[3-4]。近(jìn)年來,國內外學者提出了熱(rè)誤差模態(tài)分析法、逐步線性回歸法、模糊聚類法、神經(jīng)網絡法[5-7]等多種溫度測點的優(yōu)化布置方法。但上述測點優化布(bù)置方法(fǎ)有的過程簡單,但十分不準確,影響熱誤差模型(xíng)的準確性;有的過(guò)程十分複雜,而且需要大量(liàng)的樣(yàng)本,耗(hào)費大量的時間和(hé)成(chéng)本(běn),從(cóng)而(ér)限製(zhì)了這些方法在熱誤差建模與補償中的應用。
K-means 聚類是一種經典算法,其擁有效率高,分類(lèi)明顯(xiǎn),能對大(dà)量數據進行分割聚類等特點。該算法通(tōng)過不斷尋找新的(de)聚(jù)類中心,使得聚類效果評(píng)價函(hán)數 J 不斷收斂,直(zhí)至聚類不(bú)再變化,達到較優的聚類效果。將其與 Pearson 相關係數相結合,對機床主(zhǔ)軸溫度測點進行優化。該法在對機床主軸進行熱態特性分析的基礎上,采用 K-means 算法對熱(rè)敏區(qū)域測點的溫度特征聚類,再(zài)通過 Pearson 相關係數選出與熱變形相關性(xìng)最大的測點,實現主軸溫度測點優化。最後,對最優溫度測點進行(háng)熱誤差建(jiàn)模,並利(lì)用方差分析(xī)和 F 檢驗驗證模型(xíng)的可靠性。
2、 溫度測點優化
2.1 熱態特性(xìng)分析
在將主(zhǔ)軸導(dǎo)入 ANSYS Workbench 進行熱態特性分析之前,為減小分(fèn)析處理時龐(páng)大的計算量,需要對主軸結構進行合理簡化,簡(jiǎn)化有如下(xià)幾點:
(1)去除一(yī)些對(duì)模型熱特性影響較小的特征(如倒(dǎo)角、小孔等);
(2)主軸及箱體結構中的一些腰型孔、小(xiǎo)通孔、螺紋孔等均按實體處理;
(3)打刀缸及其附屬部件不在分析範圍內(nèi);
(4)主軸(zhóu)上的(de)小配件(jiàn)不在模型(xíng)中顯示。
完成主軸(zhóu)模型的簡(jiǎn)化後,根據所選機(jī)床的實際情況,確定熱態特性(xìng)分(fèn)析的主體為主軸以及主軸箱。主軸的熱傳遞方(fāng)式包括熱傳導、熱對流以及熱輻射。而此款立式加工中心主軸在冷卻(què)液等的作(zuò)用下,溫升較小,故忽略通過熱輻射(shè)失去的熱量,熱傳(chuán)遞方(fāng)式隻考慮(lǜ)熱傳導和熱對流(liú)。其中,熱傳導(dǎo)係數由主軸及箱(xiāng)體的材料決(jué)定,而熱對流主要考慮套筒內冷卻液的強迫(pò)對流換熱、主軸旋轉(zhuǎn)帶動(dòng)周圍空氣的流動形成的強迫對流換熱以及(jí)空氣的自然對流。由此可計算(suàn)得主軸(zhóu)的熱邊界參數[8-10],如表 1 所示(shì)。
表 1 主軸熱邊界參數

將上述已知參數在有限元分析軟件中進行設(shè)定,並進行溫(wēn)度場(chǎng)仿真,通過穩態熱分(fèn)析結果劃定出具體的熱敏區域。主軸及箱體係統(tǒng)的穩態熱分(fèn)析結果,如圖 1 所示(shì)。根據仿真結果,得知穩定後主軸最高溫度位於(yú)前端軸承,約為 32.9℃,其次為後端軸承,約為(wéi) 30.3℃,即熱(rè)敏(mǐn)區域為前後軸承之間的區域。利用該軟件中的 Probe 探(tàn)針,結合實(shí)際尺寸,初(chū)步確定熱敏(mǐn)區域範圍為[88mm,265mm]。

圖 1 主軸熱敏分析(xī)圖
2.2 K- me a ns 算法溫度聚類分(fèn)析
K-means 聚類算法是一種基於劃分法的聚類算法,它將聚類溫度集(jí)內的所有溫度(dù)樣本的均值作為該(gāi)聚類的中(zhōng)心點。其工作原理是首先從溫度測點集合中隨機選(xuǎn)取 k 個溫度測點作為初始聚類中心,分別計算各個溫度測點到初始聚類中心的相似度(以歐式距離作為相似度測量準則),並根據計算所得的距離將每個溫度測點賦給最近的聚(jù)類中心。然後再計算該溫度測點(diǎn)集合內的所(suǒ)有溫(wēn)度的平均值,得到新的聚類中心。反複循環計算,一旦連續(xù)兩次循環得到的聚類中心均為同一個溫度測點,說明溫度聚類分析完成。通常采用平方誤差函數 J 作(zuò)為聚類效果的評價函數,公式如下:

式中:P—溫度分類 Cj中任一個溫度測點;Z—溫度分類 Cj的(de)溫度聚類中心
算法流(liú)程如下:
(1)參數設定。隨(suí)機選擇 k 個溫度測點作為初始溫度聚類的中心;
(2)初始聚類。計算並比較溫度(dù)測點到每一個溫(wēn)度聚類中(zhōng)心的距離(lí),並根據最短距離聚類(lèi);
(3)修正聚類。根據新的溫度聚(jù)類,計算該溫(wēn)度聚類的平均值;
(4)聚類結果。若溫度聚類中心未(wèi)發生變化,輸出最終(zhōng)聚類結果(guǒ),循環結束,否則,返回步驟(2)繼續迭代。
2.3 相關性分析
相關性分析是用(yòng)來研究變量間關聯程度的一種統計方法,采用相關係數來表征。這裏通過比較溫度測點與熱誤差之間的Pearson 相關係數,來選出溫度聚類結(jié)果中(zhōng)每(měi)一類別裏的最優測點。相關係數 r 越大,則表明(míng)兩者間(jiān)相關性越強。公式如下:
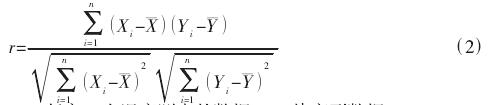
式中:X-任意有個溫(wēn)度測點的數據(jù);Y-熱變形數據。
3 、試驗(yàn)驗證(zhèng)
3.1 實驗方案
以 VMC850E 高速高精密立式加工中(zhōng)心的主軸作為實驗對象,如圖 2 所示。在前端軸承與後端軸承之間的熱敏區域,均勻布置 8 個溫度傳感器,並在主軸軸向延長線上布置一個激光位移傳感器。采(cǎi)集數據時,8 個溫度傳感(gǎn)器分別將(jiāng)采集的溫度(dù)信息(xī)和標(biāo)簽(qiān)信息打包無線發送給讀寫器,上位機(jī)通過自(zì)編的 LabVIEW 串口調試程序接收溫度(dù)信息和標(biāo)簽信息,實現信息的無線采集,最大程度上(shàng)解決了(le)一般測試方法(fǎ)布線繁雜等問(wèn)題;而激光位移(yí)傳感器將(jiāng)主軸軸向的熱變形數據通過專用的控製器傳(chuán)輸給(gěi)上位機。
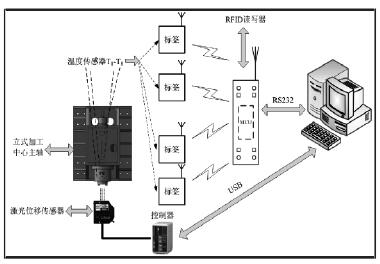
圖 2 測試係統示意圖

圖(tú) 3 現場測試圖
實驗時,設定(dìng)立式加工中心主軸轉速為 3500r/min,運轉120min,並通過自編 LabVIEW 軟件(jiàn)對溫度傳感器及激光位移傳感器同步發送命令。采(cǎi)樣間隔為 3min,並對采集的各測(cè)點溫度(dù)數據和軸向熱(rè)變形數據實時顯示、存儲(chǔ)。實驗現場測試圖,如圖 3所示。
3.2 測點優化結果
將采集得的 8 個測點的溫度數據與主軸軸向的熱變形數據,首先輸入到 K-means 算法(初始聚類)LabVIEW 求解程序當中,設定初始聚類中心個數為 2 個,分別為第 1 列和第 3 列溫度數據,初始聚類結果,如(rú)圖 4 所示。
由初始聚(jù)類程序計算結果得,第(1、5、6、7)列溫度數據分(fèn)為一(yī)類,第(0、2、3、4)列溫度(dù)數據分為另一類,並根據初始聚類的結果,求出更新中心點 0 和更新中心(xīn)點 1。
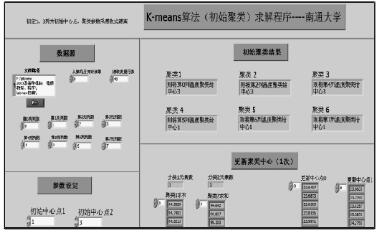
圖 4 K-means 算法(fǎ)(初始聚類)
再將更新中心(xīn)點(diǎn) 0、1 和 8 個(gè)測點的溫度數據輸入到 K-means 算法(fǎ)(修正聚類)LabVIEW 求解程序當(dāng)中,如圖 5 所示,經(jīng)過多次修正,求解出最終的更新聚(jù)類中心 0’、1’,最(zuì)終聚類結(jié)果為第(1、3、5、6、7)列溫度數據分為一類,第(0、2、4)列溫度數據分為(wéi)另一類。
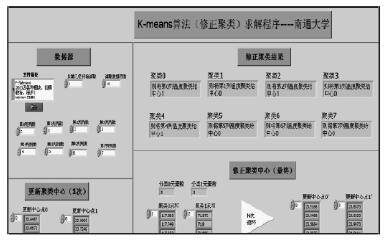
圖 5 K-均值算法(修正聚類)
最(zuì)後,由於選擇的初始聚類中心對於最終聚類結果有著很大的影(yǐng)響,且為了達到較好的聚(jù)類效果,需要選擇不同(tóng)的初始聚(jù)類中心,分(fèn)別輸入 K-means 算法求解程序中,比(bǐ)較其誤差平方和,得出最優分類結果。結果,如(rú)表 2 所示。
表 2 溫度測點聚類分析結果
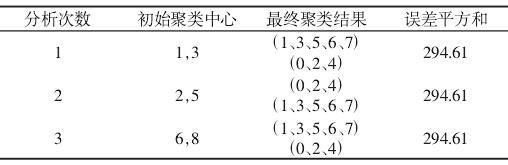
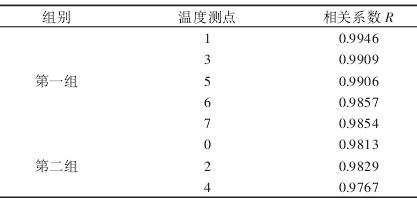
由上述結果可以看(kàn)出,由三組初始聚(jù)類中心進行(háng)聚類分析的最(zuì)終結果相同,則以此聚類結果作為最佳聚類結果。再利用 Pearson 相關係數計算各溫度測點數據與熱變形數據之間的(de)相關性,從每一類(lèi)中選出對熱變形(xíng)影響最大的一個點。
求解結(jié)果,如表 3 所示。第一(yī)類(1、3、5、6、7)中 1 號測點與熱變形之間的相關性最大(dà),第二類(0、2、4)中 2 號測點與(yǔ)熱變形之間的相關性最大,由此可知,經優化後(hòu)的最佳溫度測(cè)點(diǎn)組合為(wéi)
(1,2)。
表 3 溫度測點(diǎn)相關性求解結果
4 、回歸建(jiàn)模及分析
將最佳溫度測點(diǎn)組合(hé)(1,2)的(de)溫(wēn)度數據和軸向熱變形數據輸入到熱誤(wù)差建模程序中求解,並(bìng)通(tōng)過方差分析和 F 檢驗法對模型預測能力進行評價。設溫度值 x1、x2與(yǔ)熱變形值 y 之(zhī)間滿足如下函數關係:y=a+bx1+cx2(3)式中:x1、x2—測(cè)點 1、2 的溫度數據;y—軸(zhóu)向熱(rè)變(biàn)形數據;a、b、c—回歸係數。
若將溫度數據 x1和 x2代入式(shì)(3)即(jí)可得到相(xiàng)對的熱變形值y。利用最小二乘法,建立(lì)誤差方程並轉化為正規方程,最終矩陣化求解。為避免繁雜的計算過程,利用(yòng) LabVIEW 圖形化軟件開發
界麵友好的(de)熱誤差模型(xíng)求解程序,結果(guǒ),如圖 6 所(suǒ)示。由圖 6 可以看出,所得的熱誤差模型為 y=0.00061x1+0.00136x2-0.01055,且在給定(dìng)顯著水平 0.01 下,回歸(guī)方程 F> F0.01(2,40)=5.18,即在最佳溫度測點處監測(cè)的溫度與熱變形有顯著的線性關係,該回(huí)歸方程可較好地反映出熱變形的客觀變化(huà)規律。
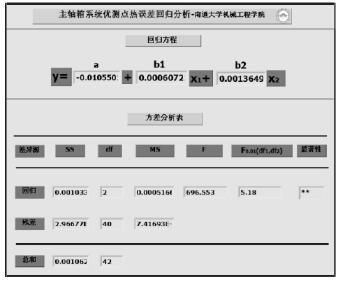
圖 6 回歸模型及 F 檢(jiǎn)驗結果
5、 結(jié)論(lùn)
(1)合理簡化主軸及箱體結(jié)構,導入 ANSYS Workbench 進行穩(wěn)態(tài)熱分(fèn)析,得出熱敏分析圖,利用主軸實際尺(chǐ)寸確定熱敏區域範圍為[88mm,265mm]。
(2)采用 K-means 算法(fǎ)對熱敏區域測點的溫度特征聚類,再通過 Pearson 相關係數選出與(yǔ)熱(rè)變形相關性最大的測點,有效地將熱(rè)敏區域內監測主軸及箱體溫度的 8 個溫度測點減少到 2 個,極大地降低了熱誤差建模的時間和成本。
(3)對優化後(hòu)的溫度測點和熱變形進行熱(rè)誤差建(jiàn)模(mó),並利用方差(chà)分析和 F 檢驗驗證,該模型可較好(hǎo)地(dì)反映出熱變形的客觀變化規律。
投稿箱:
如果您有機床行業、企業相關新聞稿件發(fā)表,或進行資訊合作,歡迎聯係本網編輯(jí)部, 郵箱:skjcsc@vip.sina.com
如果您有機床行業、企業相關新聞稿件發(fā)表,或進行資訊合作,歡迎聯係本網編輯(jí)部, 郵箱:skjcsc@vip.sina.com
更多相關信息
州金馬")
業界視點
| 更多

行業數(shù)據
| 更多
- 2024年11月 金屬切(qiē)削機床產量數據
- 2024年11月(yuè) 分地區金屬切削機床產(chǎn)量數據
- 2024年11月 軸承出(chū)口情(qíng)況
- 2024年11月 基本型乘用車(轎車)產量數據
- 2024年11月 新能源汽車(chē)產量數據
- 2024年11月 新(xīn)能源汽車(chē)銷量情(qíng)況
- 2024年10月 新能源汽車產量數據
- 2024年10月 軸承出口(kǒu)情況
- 2024年10月 分地區金屬切(qiē)削機床產量數據
- 2024年10月 金屬切削機床產量數據(jù)
- 2024年9月 新能(néng)源汽車銷量情(qíng)況
- 2024年8月 新能(néng)源汽車產量數據
- 2028年8月 基(jī)本型乘用車(轎車)產量數據
博文選萃
| 更多
- 機械加工過程圖示
- 判斷一(yī)台加工中心精(jīng)度的幾種辦法
- 中走絲線切割機床的發展趨勢
- 國產數控係統和數控機床何(hé)去何從?
- 中國的(de)技術工人都去哪裏了(le)?
- 機械老板做了十多年,為何還是(shì)小作坊(fāng)?
- 機械(xiè)行業最新自殺性營銷,害(hài)人害己!不倒閉才
- 製造業大(dà)逃亡
- 智能時代,少談點智造,多(duō)談點製造(zào)
- 現實(shí)麵前,國人沉默。製造(zào)業的騰飛,要從機床
- 一文搞懂數控車床加工刀具(jù)補償(cháng)功能
- 車床鑽孔攻螺紋加工方法及工裝設(shè)計
- 傳統鑽削與(yǔ)螺旋(xuán)銑孔(kǒng)加工工藝的區別